前言
特别声明: 本文所提供的逆向思路及代码仅供学习参考使用,请勿使用 爬虫脚本 对网站进行 高频率 以及 高并发 数据抓取操作,若对网站造成损失的,后果自负!!!
目标网址:
aHR0cHM6Ly93d3cuY2NoaW5kZXguY29tL0hvbWUvaW5kZXg
爬虫实现基本流程
一. 数据来源分析
1. 明确需求
2. 抓包分析
打开开发者工具:
点击任意一个分类:
这三个接口返回的内容都是加密的


所以目前对于这三个接口具体哪个是我们需要的接口并不清楚, 但是接口链接传入的参数, 以及返回的内容都是差不多的, 所以加密和解密的地方应该也是同样的地方
直接去逆向分析
逆向分析
逆向基本三个步骤:
定位加密/解密的位置
断点调试分析
复现加密/解密代码
请求参数: signCode 逆向
1. 定位加密位置
2. 断点调试分析
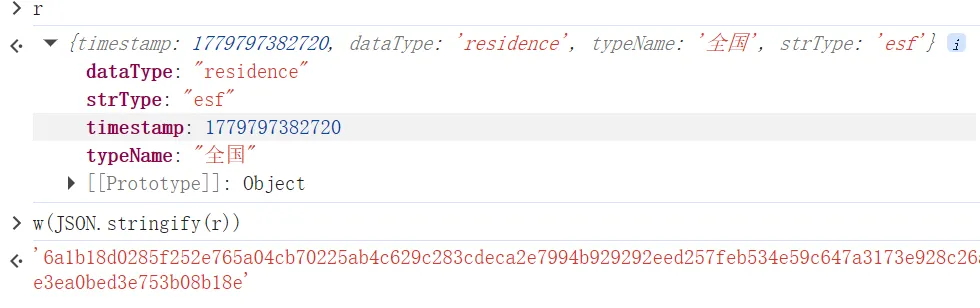
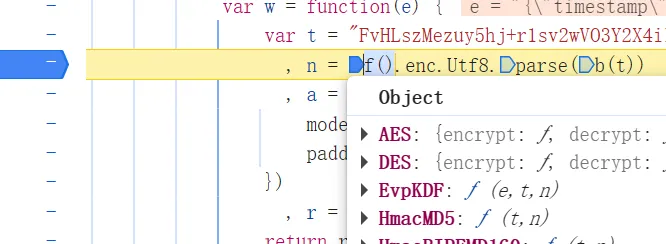
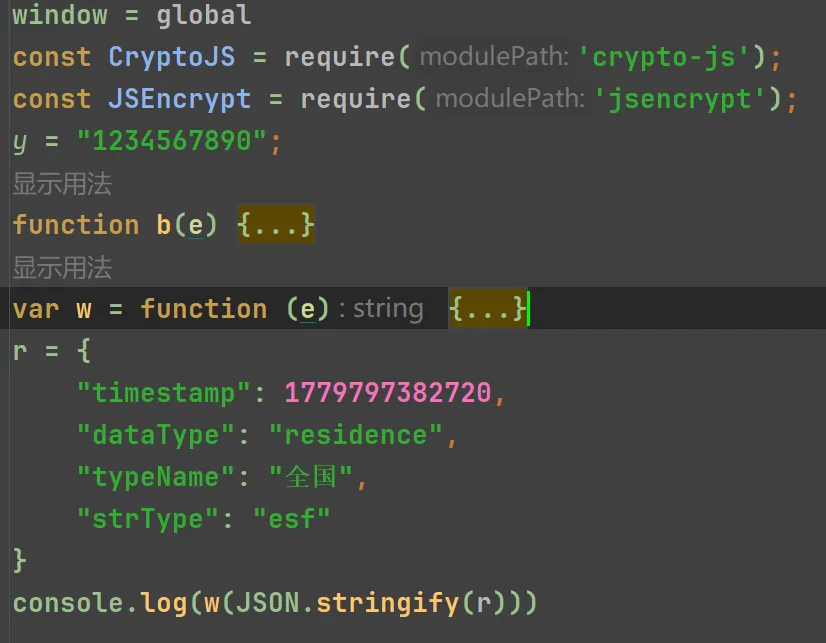
r就是明文参数, 通过JSON.stringify()把字典对象转成字符串, 再调用w()方法进行加密
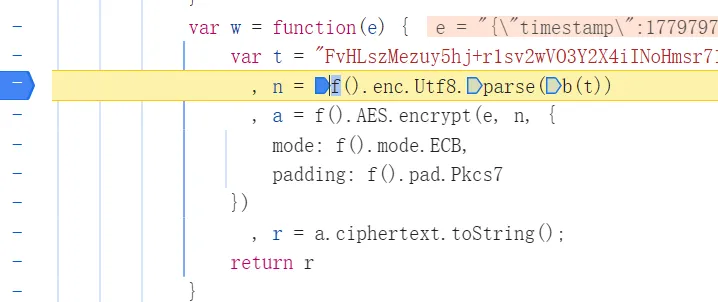
- 直接进入W方法查看具体代码内容
很明显标准的AES加密
其中还是到b()方法
RSA加密 -> 其实就是固定的一个密钥值
3. 复现加密代码
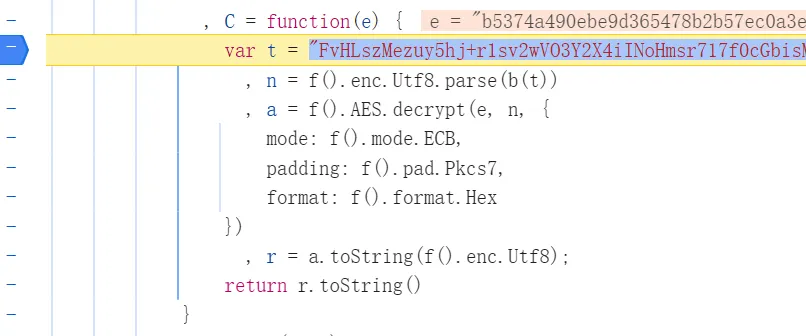
响应数据解密
和请求参数步骤类似
二. 代码实现步骤
1. 发送请求
2. 获取数据
3. 解析数据
4. 保存数据






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
